


BDRC is proud to announce a new collaboration on a scholarly project: The Authors and Translators Identification Initiative (ATII, pronounced [atiː]).
The goal of ATII is the creation of an open source collaborative database of authors, translators and other figures involved in the creation of Indic Buddhist texts and Buddhist canons – including particularly the Tibetan and Chinese ones. The ATII uses person records instead of name records, and thus disambiguates names when multiple persons have the same name or one person has multiple names. This methodology has never been applied before in the case of the Tibetan Canon. Projects participating in the initiative are BuddhaNexus, BDRC, and Resources for Kanjur and Tanjur Studies (rKTs, University of Vienna). The first stage of the collaboration is now online on BUDA and is a significant refinement on the existing data! The data is open source and collaborations are envisioned with other projects like 84000.
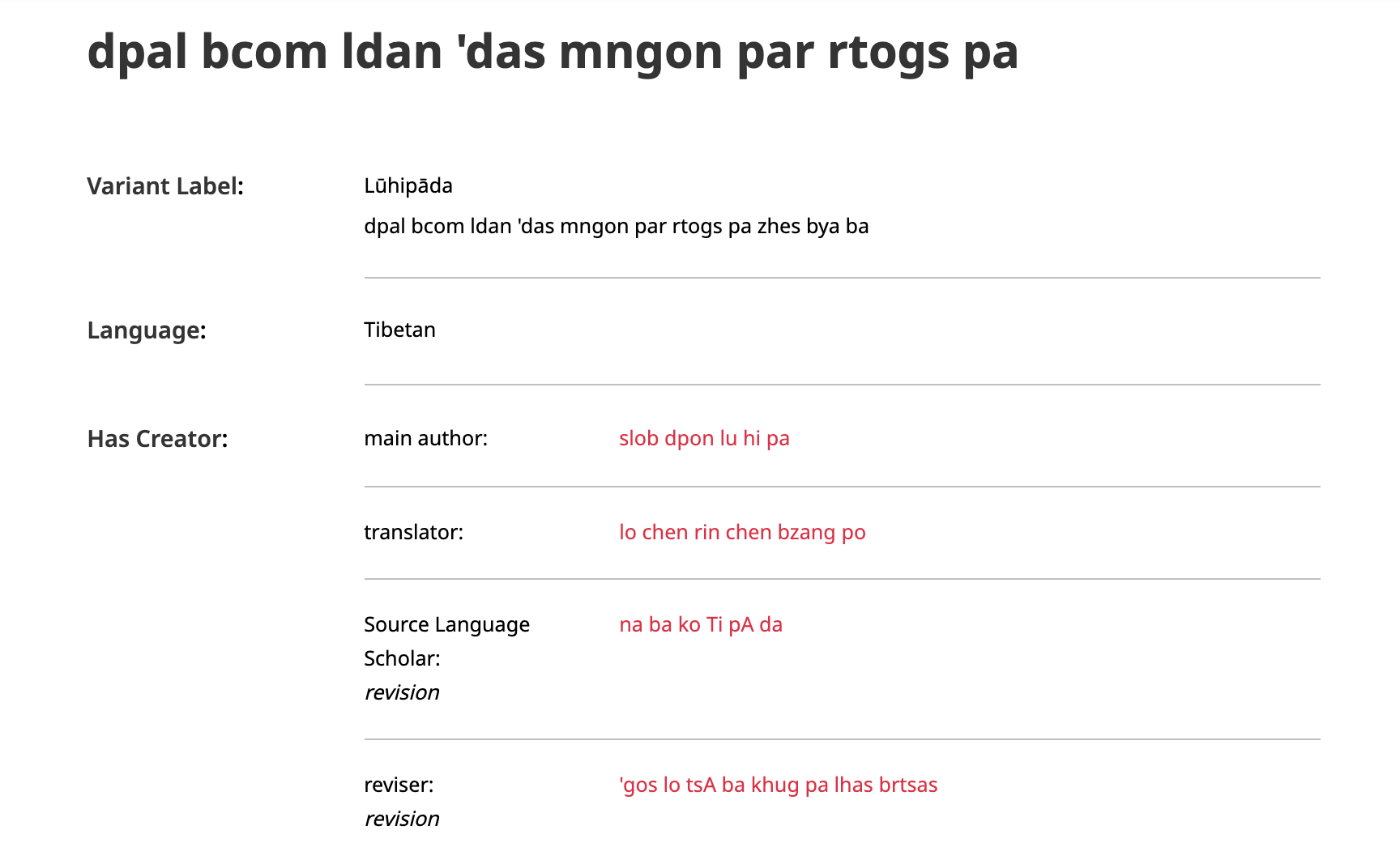
The catalogue record for Lūhipāda or dpal bcom ldan 'das mngon par rtogs pa.
The team working on the Indo-Tibetan part of ATII mainly consists of Orna Almogi, Nicola Bajetta, and Ryan Conlon, closely collaborating with Élie Roux from BDRC. The basis of the data is BDRC's person records and canonical texts attributions (authors and translators). The primary goal of ATII is to have a better identification of the relevant persons, with their dates, origins, networks, etc. through new research into primary and secondary sources. The team has also created innovative tools to check the temporal coherence of the data, based on assumptions that the dates of a translator and a paṇḍita who worked together must necessarily overlap; translators cannot predate the author of the text they translated, and the like.
In the first stage, we looked at all the colophons of the Derge Kangyur and Tengyur and created a one of a kind database of 1050 persons (300 Tibetans and 750 non-Tibetans, including 500 authors). More than 250 person records have already been added to BUDA, and dozens of duplicate records have been merged. Many authors of Indic texts represented in the Gretil corpus have also been added during this first stage. The translation and authorship attributions visible now on BUDA (at the level of Work) all come from ATII, and they will continue to be refined until the end of the project. In the next stages, the team intends to compare the data with other canonical collections and catalogs (particularly the Peking Tengyur) that have more texts and sometimes different attributions than what can be found in the Derge canon.

Derge Kangyur in the Buddhist Digital Archives.
The second team, which concentrates on linking Indic persons and their works to the Chinese Buddhist Canon, includes Sebastian Nehrdich and Marco Hummel and enjoys collaboration with Michael Radich and Jamie Norrish of the Chinese Buddhist Canonical Attributions database (CBC@). We hope to widen our cooperation in the future to cover this corpus as well.
The ATII team situated in Hamburg is financially supported by Khyentse Center, Universität Hamburg under the directorship of Prof. Dr. Dorji Wangchuk.
If you are interested in more information or in collaboration, please contact help@bdrc.io.
Sorry, the comment form is closed at this time.