

This is the age of Artificial Intelligence (AI), which raises questions for all of us. How are we going to use AI? How can AI help us do our work better and faster? What is the future of AI? Here at the Buddhist Digital Resource Center, at the cutting edge of Buddhist Digital Humanities, these questions are especially relevant. And we are already answering some of them. Our developer Élie Roux's article below describes a novel approach to an old problem, the problem of cataloging. Can AI help our archive speed up the work of librarians and technicians with our backlog of millions of pages of scanned texts? This isn't just a thought exercise for us. Élie describes a special project that uses both AI and the specialized and human work of our librarians. The success of this project shows us a path forward, one where AI is among a suite of technologies that librarians and preservationists use to further the mission of preserving and advancing knowledge in the world. Please read on.
An Account of BDRC's First In-House AI Model
By Élie Roux
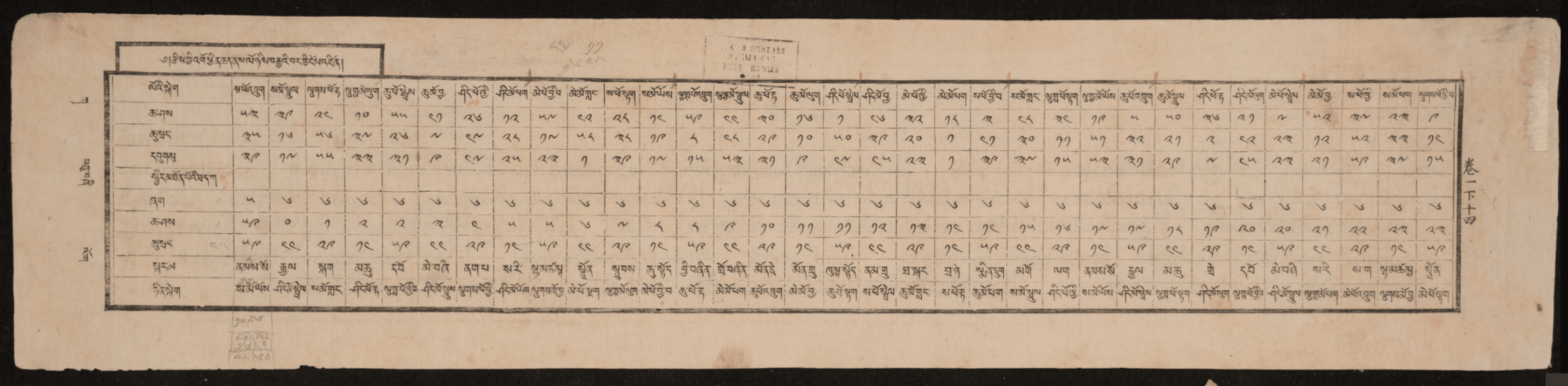
Illustration from an astronomy text. A table of values (source), from the Tibetan translation of the Tengri-yin udq-a, Essence of Heaven, itself a translation of the Chongzhen lishu 崇禎曆書, Calendrical Treatise of the Chongzhen Reign, of c.1635.
Abstract
Given a large collection of 1.4 million scanned images of 5,000 text volumes and a catalog of 84,000 text titles, how can AI help us map the titles to their corresponding images? This article is an account of a successful project that used AI with humans in the loop to map these titles to their corresponding images by detecting library stamps on scanned images. We lay out our methodology and the various technical and non-technical challenges that arose in the process.
Introduction
Context
Since 2018 (?), the Buddhist Digital Resource Center (BDRC) has been working in collaboration with Asian Legacy Library (ALL) on a project to digitize the Tibetan collection at the National LIbrary of Mongolia (NLM). As of March 2023, 5,897 volumes have been put online, in open access, on the BDRC website. We estimate that this represents about 20% of the overall Tibetan collection. We would like to thank the Khyentse Foundation for sponsoring the project. Please read the corresponding BDRC blog post for more information.
Before the volumes are digitized, the librarians at the National Library:
- Add a stamp on the left hand side of the first page of each text in a volume and write an accession number next to the stamp
- Produce a very detailed catalog of each text, referencing their volume and accession number

A typical example of a page with a red stamp and an accession number (written vertically) on the left
BDRC's platform allows users to explore collections by providing a table of contents that is connected to the images, so that clicking on a text opens the scans of the particular text instead of having to find it in the scans of a volume. BDRC wants to offer the same level of integration to the volumes of the NLM.
In the case of this particular collection, it is really crucial to have information about the different texts in a volume because in many cases the volumes are in fact bundles (or codices), composed of text of different natures: some are manuscripts, others are xylographs, the paper size can be different, etc. The various texts in a volume are often completely unrelated and having information about the first text in a volume doesn't help you access or discover the following texts. This is a very different situation from a case where the volume is a well known collection, or where it is one text composed of multiple chapters.
Once the volumes are scanned, the images are sent to BDRC—one folder per volume. This means that when we import the catalog made by the librarians at the NLM, we cannot connect it with the image numbers and take advantage of the features of the BDRC platform. We thus decided to explore automating the link between the catalog and the images by detecting the stamps on the scanned images.
Discussions were initiated on January 22, 2023 by BDRC and involved a network of experts, primarily Eric Werner at Hamburg University, who designed and wrote all the AI-related parts. This project would not have been possible without him.
The Solution
Defining the Task
Different methods were envisioned:
- Passing the rotated images to Google Vision for OCR
- Doing a full layout detection model where NLM numbers and stamps would be recognized
- Using binary classification and training a model to recognize if a stamp is present or not
We chose the third method as it required the least training data and gave the best results on images where the stamp was difficult to read (where the OCR would not have recognized anything).
Generating Training Data
Artificial intelligence (AI) requires large amounts of training data, which is then used to train machine learning models. The data is usually labeled, meaning that each data point is tagged with relevant information, such as its category or classification. The machine learning model uses this labeled data to learn patterns and relationships between the input data and the output predictions. The more diverse and representative the training data is, the more accurate and robust the AI system will be. However, the process of gathering and labeling training data can be time-consuming and expensive.
In order for an AI to be trained, the first step was to gather training data. Ideally this data would consist of two lists, ideally of the same length:
- Images with a stamp
- Images with no stamp
We needed at least a few thousand images with and without stamps to start training the model. Going through a few volumes and listing the images with the stamps would have required a very long time, and a few hundred volumes would have had to be browsed in this way, which seemed like an unnecessarily time consuming option.
Instead we took advantage of the fact that in 99% of the volumes, among the first two images, only one will have a stamp. We took the following steps:
- Downloaded the first two images of thousands of volumes, rotated them and cropped them so that the area with the potential stamp was very visible
- Saved the list of files
- Browsed through the images using the OS file explorer and removed all the images with a stamp
- Compared the resulting file list with the original to obtain a list of images with and without stamps

Image Classification
A first classification model was fine-tuned for 20 epochs on MobileNetV2 using ImageNet weights using 4,485 positives and 3,760 negatives. The model achieved an accuracy of 0.9628 and a val_accuracy of 0.9430.
The model was then used to run inference on 101,239 images not in the training data (about 7% of the total), giving a probability of the presence of a stamp on each image.
The results were then analyzed in the following manner:
- All the results with a probability of 0 or 1 were reviewed (following the same method as the constitution of the training data)
- The results were compared with the catalog (which indicates how many stamps are present in theory). This allowed us to detect cases where the model detected more stamps than present in theory. We then downloaded all the positives from the volumes where this happened and reviewed the results manually
- In some cases as many as 4 numbers were present on the same page
The results of the review were then integrated in the training data, adding in total:
- 1,090 positives
- 3,042 negatives
An additional 4,773 positives were contributed by Bruno Lainé of the Resources for Kangyur and Tengyur Studies (rKTs) project in Vienna who manually checked the first 400 volumes.
To balance the two datasets (positives and negatives), we used a script to list files that we know are negatives from the catalog (for volumes with only one text or volumes where all the stamps have been identified).
Second iteration
A second model was trained from scratch based on a simplified Xception-architecture [1] for 25 epochs using 18,000 samples from the NLM collection, of which 10,800 were used for the training set, and 3,600 for the test and evaluation set respectively. The model was trained end-to-end on the original images performing the necessary cropping and resizing (224 x 224px) as part of the input pipeline.
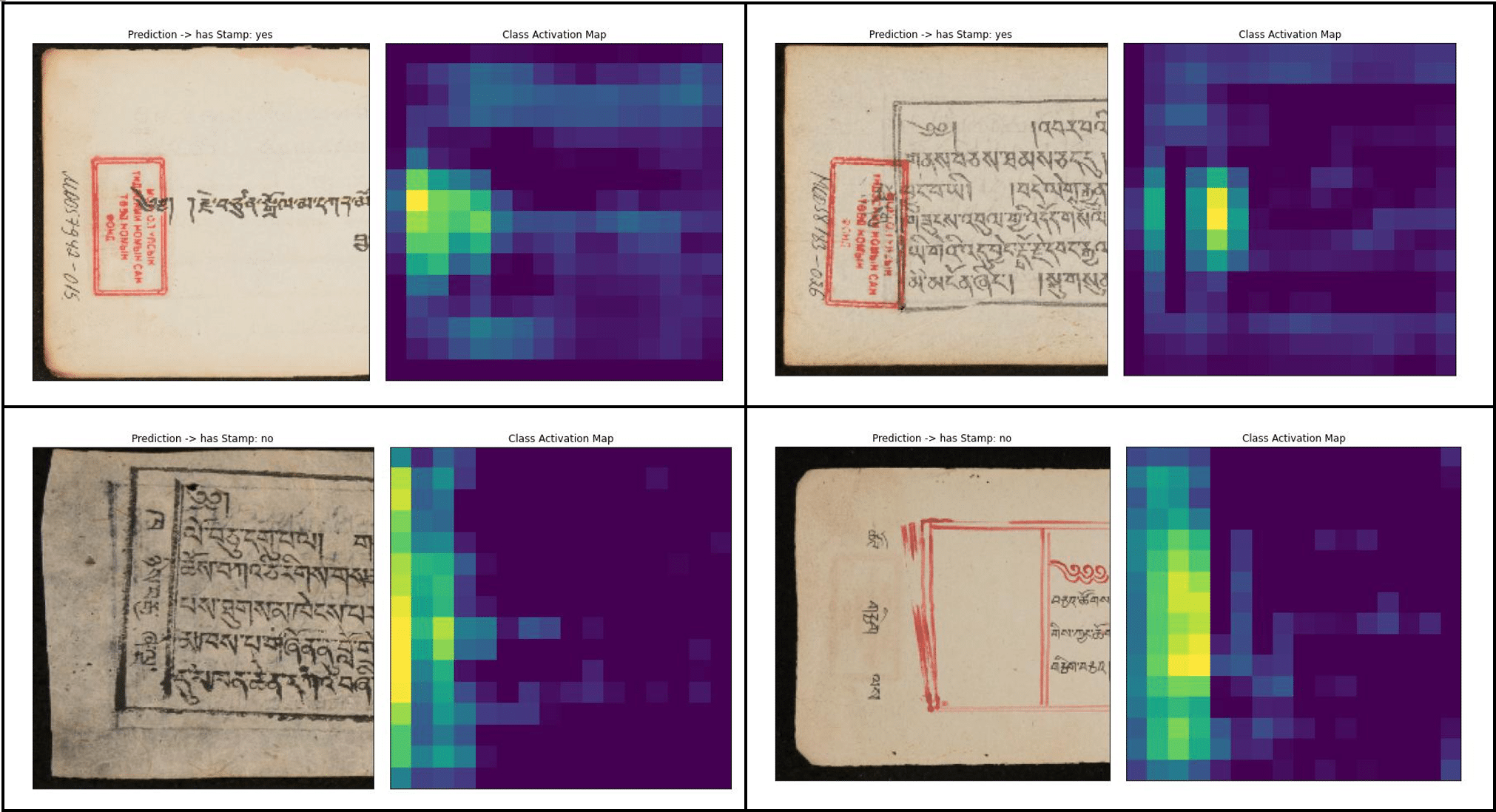
Visualization of the Class Activation Maps for correct predictions for detected stamps (top) and missing stamps (bottom)
A new model was then trained on this updated training data. The quality of this new model was deemed sufficient for a full analysis.
The inference for this second model was then run on all the volumes where the catalog indicates multiple texts, or 1,432,506 images. The inference was run for three days on two different machines in the cloud (one starting from the end of the list):
- One is an instance with a small GPU
- One is an instance with a 4-core CPU and no GPU
An estimate is that the instance with the GPU was about twice as fast as the instance with no GPU.
The results were then analyzed using the same method as the previous one. All the images reviewed manually were added to the list of training data, giving a total of:
- 8,303 negatives
- 25,949 positives
Comparing the results with the catalog:
- The model detected the expected number of stamps in 4,268 volumes (85,339 stamps in total for these volumes)
- The model detected more stamps than expected in 52 volumes
- The model detected less stamps than expected in 752 volumes
These discrepancies had a variety of explanations:
- Some of the texts (mostly duplicates) present in the catalog were not actually scanned, and thus there were no stamps to detect (images for 1,730 texts are missing, in 386 volumes). This information was not present in the catalog
- In some cases no stamps were present on the images even where they were expected
- In a few cases the stamp was on the right hand side of the image and could not be detected by the model
- For some images the model performed poorly, especially for very large books where the stamp is comparatively small on the image (example)
- The catalog sometimes has typos in the volume name or puts texts in the wrong volume
Final Stage
The final stage of the project was to look at all of the 804 volumes with discrepancies and manually reconcile the catalog with the images.
In many cases, the issue was that the model did not detect just one or two stamps in a volume. In order to speed up the manual review, we:
- Downloaded all the positive results from volumes with less positives than expected from the catalog
- Listed all the files
- Looked at each file individually and remove the files corresponding to stamps that are sequentially after the missing stamps (i.e.: if we have stamp 1, stamp 2, stamp 4, we remove stamp 4 to indicate that stamp 3 is missing)
- Compared the list
Of course this did not work for volumes with a lot of discrepancies but this step helped speed up the manual review tremendously, allowing reviewers to focus on one small part of the volume instead of having to browse the full set of images and check each stamp.
The review process then happened in a spreadsheet that was pre-filled with pages where the model detected a stamp. This step still took about 6 full days for the three BDRC librarians, although a few other tasks were performed at the same time, such as reconstructing missing titles.
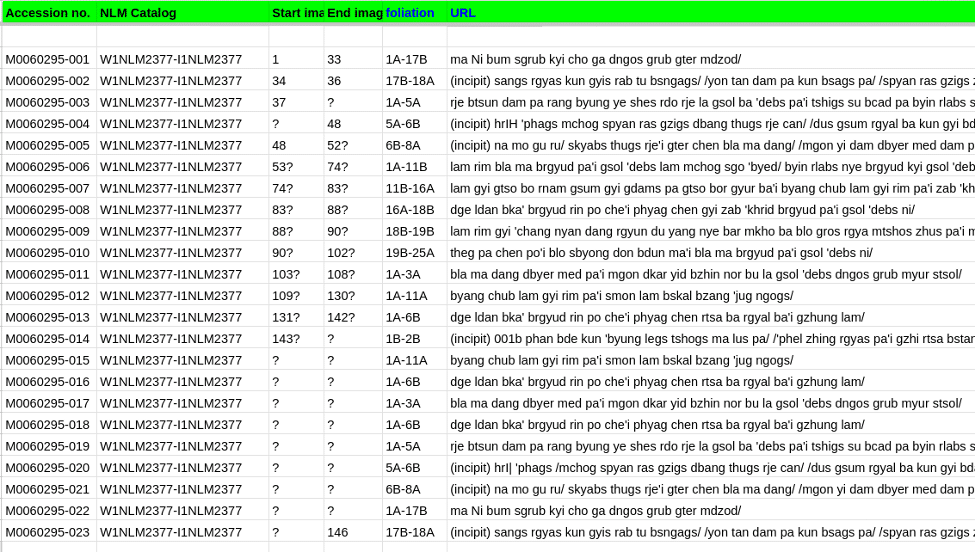
Example of pre-filled spreadsheet to be manually reviewed. Note that the intermediate stage allowed us to spot that stamp number 4 was not detected, but it was easy to find thanks to the foliation information (column E) indicated in the NLM catalog.
Once this exercise was completed we were able to compute some statistics for the model:
precision = 0.989628
recall = 0.988978
f = 0.989303
We can only speculate how much time it would have taken to do all the reconciliation of the catalog with the images without this tool, but it is clear that it saved our staff months of full time work. Actually, without the possibility of automation to accelerate the process, we might not have undertaken this project at all.
The outlines of the texts were imported on the BDRC website on March 17 2023, only 55 days after the project was first envisioned, a stunning success. Here's an example of an outline that can be browsed in the archive: https://purl.bdrc.io/resource/MW1NLM2106.
Conclusion
This project is a great example of how a simple AI mechanism with humans in the loop can save months of work on cultural heritage projects. Over the course of 2 months, an impressively accurate AI model allowed BDRC to match nearly 84,000 titles with 1,4 million images.
Sorry, the comment form is closed at this time.